
I am a researcher at Tencent Hy, pre-training team. My research focuses on the reliability and predictability of large language models — understanding their behavior and developing principled training that keeps it stable across scales, architectures, and training recipes. Currently, I work on scaling laws for pre-training, making model behavior predictable as models scale.
I received my M.S. from the Department of Automation at Tsinghua University, supervised by Prof. Rui Jiang.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "News
Education
-
 Tsinghua UniversityDepartment of Automation
Tsinghua UniversityDepartment of Automation
M.S. StudentSep. 2020 - Jun. 2023 -
 Beijing Normal UniversityCollege of Information Science and Technology
Beijing Normal UniversityCollege of Information Science and Technology
B.S. in Computer ScienceSep. 2016 - Jun. 2020
Honors & Awards
-
Outstanding Graduate of Beijing, Beijing Municipal Commission of Education2020
-
Merit Student of Beijing, Beijing Municipal Commission of Education2020
-
National Scholarship, Chinese Ministry of Education2019
-
Meritorious Winner of Mathematical Contest in Modeling2019
-
Excellent Student Cadre, Beijing Normal University2017, 2018, 2019
Experience
-
 Tencent HyResearcherNov 2024 - Present
Tencent HyResearcherNov 2024 - Present -
 Microsoft Research AsiaResearch Intern, advised by Haoyang Huang and Dongdong ZhangJun 2022 - Apr 2023
Microsoft Research AsiaResearch Intern, advised by Haoyang Huang and Dongdong ZhangJun 2022 - Apr 2023 -
 WeChat AIResearch Intern, advised by Hao Zhou and Yankan LinOct 2021 - Apr 2022
WeChat AIResearch Intern, advised by Hao Zhou and Yankan LinOct 2021 - Apr 2022 -
 Baidu Search ScienceResearch Intern, advised by Tianshu LyuSep 2020 - May 2021
Baidu Search ScienceResearch Intern, advised by Tianshu LyuSep 2020 - May 2021
Selected Publications (view all )
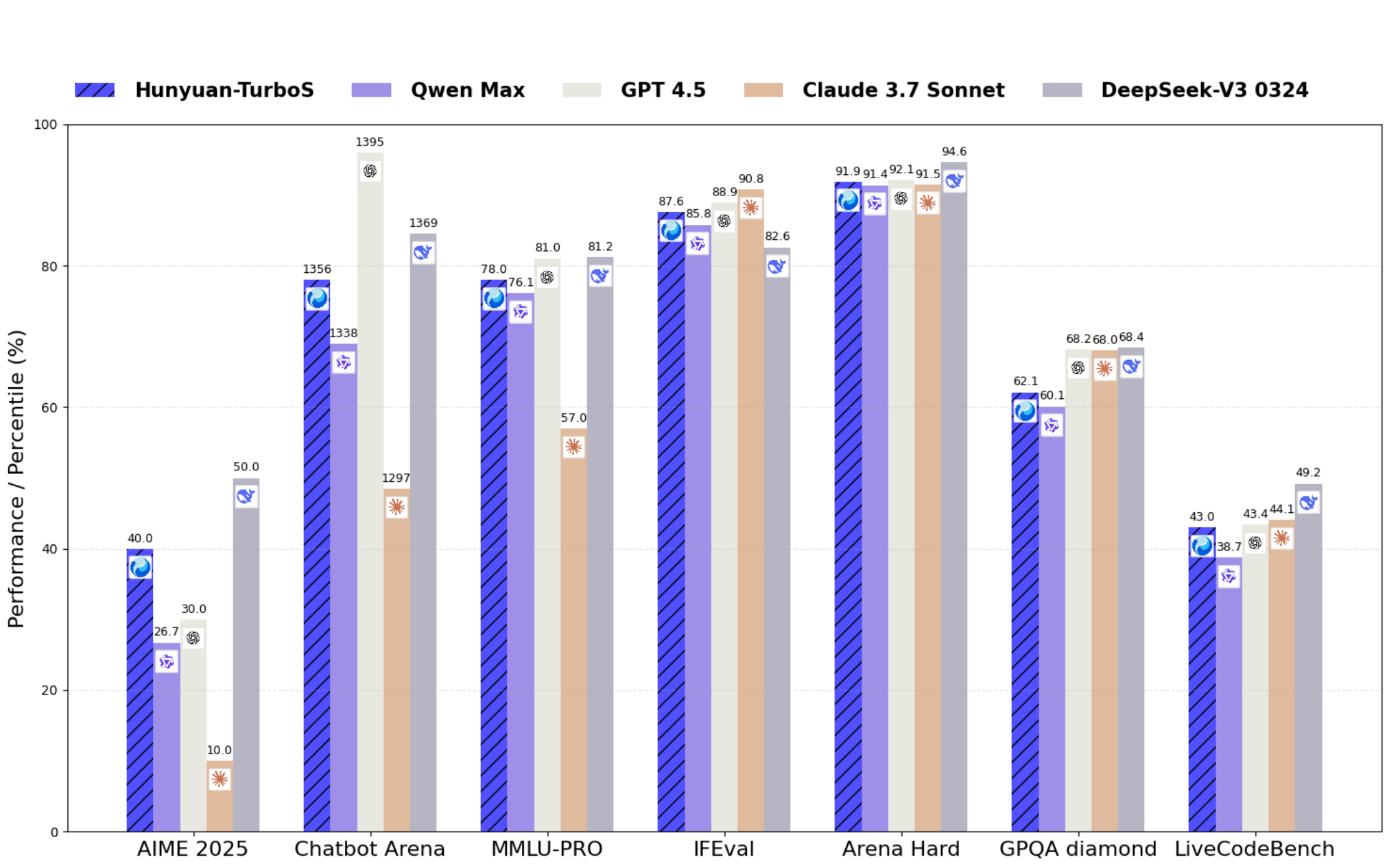
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
Hunyuan Team
arXiv 2025
Abstract
As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba’s long-sequence processing efficiency with Transformer’s superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep ”thinking” modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multiround Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
Hunyuan Team
arXiv 2025
Abstract
As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba’s long-sequence processing efficiency with Transformer’s superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep ”thinking” modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multiround Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
ROSE: Robust Selective Fine-tuning for Pre-trained Language Models
Lan Jiang*, Hao Zhou*, Yankai Lin, Peng Li, Jie Zhou, Rui Jiang (* equal contribution)
The Conference on Empirical Methods in Natural Language Processing (EMNLP) 2022
Abstract
Even though large-scale language models have achieved excellent performance, they suffer from various adversarial attacks. A large body of defense methods has been proposed, but they are still limited due to redundant attack search spaces and the inability to defend against diverse attack types. In this work, we present a novel fine-tuning approach called RObust SElective fine-tuning (ROSE) to address this issue. ROSE conducts selective updates when adapting pre-trained models to downstream tasks, filtering out invaluable and unrobust parameter updates. Specifically, we propose two strategies: first-order and second-order ROSE, for selecting target robust parameters. Experimental results show that ROSE achieves significant improvements in adversarial robustness on various downstream NLP tasks, and the ensemble method even surpasses both variants above. Furthermore, ROSE can be easily incorporated into existing fine-tuning methods to further improve adversarial robustness. Empirical analysis confirms that ROSE eliminates unrobust spurious updates during fine-tuning, leading to solutions corresponding to flatter and wider optima than the conventional method. Code is available at https://github.com/jiangllan/ROSE.
ROSE: Robust Selective Fine-tuning for Pre-trained Language Models
Lan Jiang*, Hao Zhou*, Yankai Lin, Peng Li, Jie Zhou, Rui Jiang (* equal contribution)
The Conference on Empirical Methods in Natural Language Processing (EMNLP) 2022
Abstract
Even though large-scale language models have achieved excellent performance, they suffer from various adversarial attacks. A large body of defense methods has been proposed, but they are still limited due to redundant attack search spaces and the inability to defend against diverse attack types. In this work, we present a novel fine-tuning approach called RObust SElective fine-tuning (ROSE) to address this issue. ROSE conducts selective updates when adapting pre-trained models to downstream tasks, filtering out invaluable and unrobust parameter updates. Specifically, we propose two strategies: first-order and second-order ROSE, for selecting target robust parameters. Experimental results show that ROSE achieves significant improvements in adversarial robustness on various downstream NLP tasks, and the ensemble method even surpasses both variants above. Furthermore, ROSE can be easily incorporated into existing fine-tuning methods to further improve adversarial robustness. Empirical analysis confirms that ROSE eliminates unrobust spurious updates during fine-tuning, leading to solutions corresponding to flatter and wider optima than the conventional method. Code is available at https://github.com/jiangllan/ROSE.

On Length Divergence Bias in Textual Matching Models
Lan Jiang, Tianshu Lyu, Yankai Lin, Meng Chong, Xiaoyong Lyu, Dawei Yin
Findings of the Association for Computational Linguistics (ACL) 2022
Abstract
Despite the remarkable success deep models have achieved in Textual Matching (TM) tasks, it still remains unclear whether they truly understand language or measure the semantic similarity of texts by exploiting statistical bias in datasets. In this work, we provide a new perspective to study this issue --- via the length divergence bias. We find the length divergence heuristic widely exists in prevalent TM datasets, providing direct cues for prediction. To determine whether TM models have adopted such heuristic, we introduce an adversarial evaluation scheme which invalidates the heuristic. In this adversarial setting, all TM models perform worse, indicating they have indeed adopted this heuristic. Through a well-designed probing experiment, we empirically validate that the bias of TM models can be attributed in part to extracting the text length information during training. To alleviate the length divergence bias, we propose an adversarial training method. The results demonstrate we successfully improve the robustness and generalization ability of models at the same time.
On Length Divergence Bias in Textual Matching Models
Lan Jiang, Tianshu Lyu, Yankai Lin, Meng Chong, Xiaoyong Lyu, Dawei Yin
Findings of the Association for Computational Linguistics (ACL) 2022
Abstract
Despite the remarkable success deep models have achieved in Textual Matching (TM) tasks, it still remains unclear whether they truly understand language or measure the semantic similarity of texts by exploiting statistical bias in datasets. In this work, we provide a new perspective to study this issue --- via the length divergence bias. We find the length divergence heuristic widely exists in prevalent TM datasets, providing direct cues for prediction. To determine whether TM models have adopted such heuristic, we introduce an adversarial evaluation scheme which invalidates the heuristic. In this adversarial setting, all TM models perform worse, indicating they have indeed adopted this heuristic. Through a well-designed probing experiment, we empirically validate that the bias of TM models can be attributed in part to extracting the text length information during training. To alleviate the length divergence bias, we propose an adversarial training method. The results demonstrate we successfully improve the robustness and generalization ability of models at the same time.

MAssistant: A Personal Knowledge Assistant for MOOC Learners
Lan Jiang, Shuhan Hu, Mingyu Huang, Zhichun Wang, Jinjian Yang, Xiaoju Ye, Wei Zheng
The Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) System Demonstrations 2019
Abstract
Massive Open Online Courses (MOOCs) have developed rapidly and attracted large number of learners. In this work, we present MAssistant system, a personal knowledge assistant for MOOC learners. MAssistant helps users to trace the concepts they have learned in MOOCs, and to build their own concept graphs. There are three key components in MAssistant:(i) a large-scale concept graph built from open data sources, which contains concepts in various domains and relations among them;(ii) a browser extension which interacts with learners when they are watching video lectures, and presents important concepts to them;(iii) a web application allowing users to explore their personal concept graphs, which are built based on their learning activities on MOOCs. MAssistant will facilitate the knowledge management task for MOOC learners, and make the learning on MOOCs easier.
MAssistant: A Personal Knowledge Assistant for MOOC Learners
Lan Jiang, Shuhan Hu, Mingyu Huang, Zhichun Wang, Jinjian Yang, Xiaoju Ye, Wei Zheng
The Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) System Demonstrations 2019
Abstract
Massive Open Online Courses (MOOCs) have developed rapidly and attracted large number of learners. In this work, we present MAssistant system, a personal knowledge assistant for MOOC learners. MAssistant helps users to trace the concepts they have learned in MOOCs, and to build their own concept graphs. There are three key components in MAssistant:(i) a large-scale concept graph built from open data sources, which contains concepts in various domains and relations among them;(ii) a browser extension which interacts with learners when they are watching video lectures, and presents important concepts to them;(iii) a web application allowing users to explore their personal concept graphs, which are built based on their learning activities on MOOCs. MAssistant will facilitate the knowledge management task for MOOC learners, and make the learning on MOOCs easier.